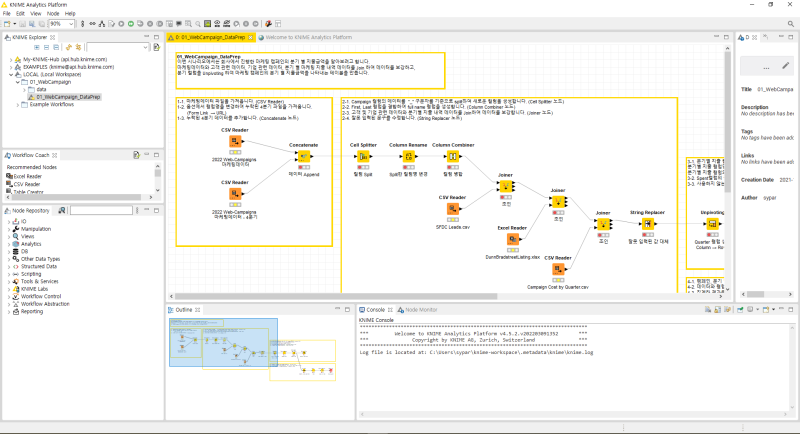
KNIME 툴의 기본 지식을 익히기 위해 EXEM사가 작성한 ‘KNIME을 활용한 BIG DATA 분석’ 도서를 활용했다. 본은 데이터 분석 과정(데이터 가공-데이터 전처리-데이터 탐색-데이터 분석)시 주로 사용되는 커넥터의 특성에 대해 설명해준다. 데이터 분석 과정에 대한 상세한 설명은 없다. ‘각 커넥터별 사용설명서(한국어 VER)’ 정도로 이해하면 될 것 같다. 사용후기

“작업 흐름 기반”사실은 이 단어가 KMINE을 설명하는 가장 명확한 말이다.기존 CUI방식(코딩)에서 VPL방식으로의 이동은 많은 변화를 가져왔다.첫째, 직관성이다.워크 플로가 직관적으로 보이는 문제 여부가 각 커넥터상에서 표현됨으로써 명확하게 오류를 인지할 수 있었다.그리고 저의 모델 구성이 어떻게 진행하거나 길에 서슴없이 따라갈 수 있었다.둘째, 효율성이다.코딩으로 모델을 구축하려면 각 패키지별 특성을 이해할 시간이 필요하다.예를 들어 Python상의 Seaborn, Pytorch, Keras등 ML과 관련된 패키지의 사용은 조금씩 다르다.그러나 KNIME상에는 이런 차이는 없다.다만 적절한 커넥터를 찾아 접속하면 좋다.다음의 스텝 커넥터를 찾아가는 과정도 간단하다.빅 데이터에 근거하여 커넥터를 추천하는 단계를 가는 과정이 어렵지 않다.셋째, 개방성이다.커넥터에서 쉽게 구축하는 것의 장점도 있지만 물론 단점도 존재한다.통제할 영역이 확실하게 적어졌다.예를 들어 Pythorch에서 내가 조정할 수 있는 변수와 KNIME에서 조정할 수 있는 변수의 수는 분명히 차이가 있다.또 R로 다루는 Partitioning방법과 KNIME에서 방법의 수에는 차이가 있다.단순화 때문에 KNIME은 몇몇 기능을 포기했다.그러나 이를 프로그래밍 간 연동으로 극복한다.KNIME은 R, Python, Java등 다양한 도구의 연동을 통해서 이를 보완한다.향후 계획

아직 완벽하지는 않지만 이 매력적인 도구를 공부하면서 문법을 배운 느낌이다. 실제로 CUI 코딩만으로도 쉽게 문법을 배워 자신만의 문체를 만들어가는 이들도 많다. 그러나 나는 그러지 못하고 사경을 헤매고 있었다. 하지만 이제 문법에 대해 눈이 뜨기 시작하면서 문체를 바라볼 수 있는 수준이 된 것 같다. 좀 더 나은 모델을 구축하기 위해서는 수리통계, 선형대수 등 코딩에서 벗어난 이론에 대한 많은 공부가 필요하다고 생각한다. 앞으로는 그런 분야에 대한 공부를 병행해 볼 것이다. KNIME을 완전히 손에서 놓지 않을 것이다. Kaggle, Daycon 예시를 바탕으로 KNIME의 다양한 커넥터 공부를 병행한다. 천천히 나만의 문체를 만들기 위해 다시 나아가보자.